本次澳洲作业是一个R统计的Lab统计代写
Goals:
(i) Fit and interpret the simple regression model in R;
(ii) Check model assumptions;
(iii) Explore more general estimation methods beyond the least squares method.
Data: In this lab, we will use the crime data from Agresti and Finlay (1997), describing crime rates in the United States. The variables are state ID (sid), state name (state), violent crimes per 100,000 people (crime), murders per 1,000,000 people (murder), the percentage of the population living in metropolitan areas (pctmetro), the percentage of the population that are white (pctwhite), the percentage of the population with a high school education or above (pcths), the percentage of the population living under the poverty line (poverty), and the percentage of the population that are single parents (single). Data can be obtained from the shared folder in the computer labs, from the LMS, or downloaded from
https://stats.idre. ucla.edu/stat/data/crime.dta. The data file is in the Stata binary format (.dta) so you will need to install the foreign package to import it into R.
1 Explore pairwise associations
R can import and export data in different formats. For example, the crime.dta data file is produced by Stata, a commercial statistical software package. The R package foreign defines useful functions to manipulate data formats different from .csv or .txt. If you working on your own computer (rather than the lab machines), you might need to install it first:
install.packages(“foreign”)
Now we can load the data and compute some basic summary statistics:
library(foreign)
cdata <- read.dta(“crime.dta”)
summary(cdata)
1. Explore pairwise association between variables by constructing a scatter plot matrix. We are interested in finding variables related to crime.
plot(cdata[, -c(1, 2)])
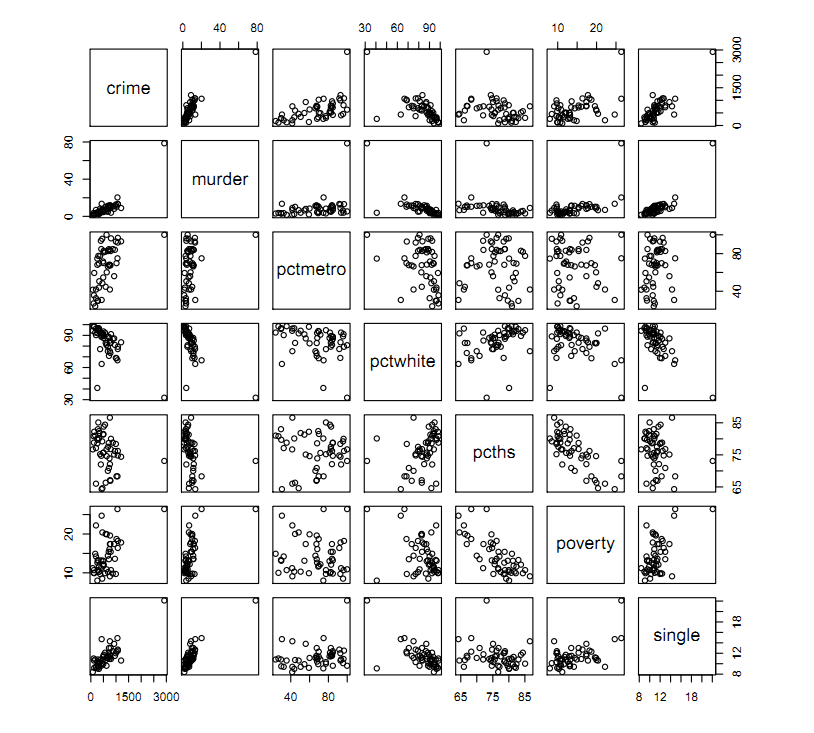
We excluded the first two columns since they do not contain numerical variables. Often
transforming the variables by the log() function helps us see linear association between
variables.
plot(log(cdata[, -c(1, 2)]))